AI Data Governance
& Lineage: BuBuildin
Trustworthy AI Pipelines
Most AI failures begin with dirty data – and the EU AI Act will ask for your lineage proof.
That’s not a hypothetical. High-risk AI systems – credit scoring, medical diagnostics, HR screening – now require documented data governance frameworks and full audit trails as a legal obligation. If you can’t show where your training data came from, how it was validated, and who signed off on it, you have a compliance problem, not just a technical one.
This article covers what AI data governance actually requires in 2026: the EU regulatory baseline, practical strategies to manage data quality and lineage across your AI lifecycle, the tools worth using, and the real-world failures that happen when governance is skipped.
What is Data Governance?
Quick answer:
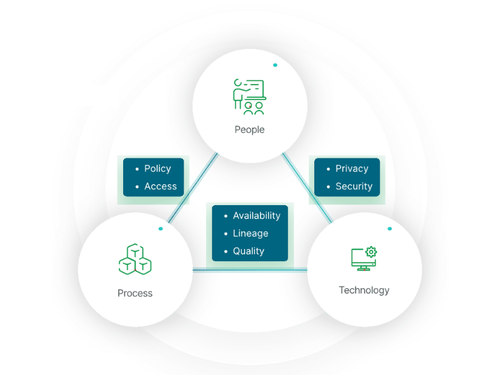
Data governance is a comprehensive framework of policies, roles, and standards that ensures an organization’s data is accurate, available, and secure throughout its lifecycle. It acts as a set of rules for managing data as a strategic asset, focusing on quality, privacy, and compliance to support decision-making, analytics, and AI innitiatives
The goal of data governance is to maintain safe, high-quality data that is easily accessible for data discovery, business intelligence initiatives and AI efforts. Acting rather like an air traffic control hub, the data governance function helps ensure that verified data flows through secured pipelines to trusted endpoints and users.
Why Data Governance Matters for AI
Quick answer:
Data Governance is the Backbone of Reliable AI. It directly determines the reliability, safety, and legality of AI models. AI systems are only as effective as the data used to train them; poor-quality data leads to “garbage in, garbage out,” resulting in biased, inaccurate, or harmful outcomes. As AI moves from experimentation to business operations, robust governance provides the necessary guardrails to turn chaotic data into a secure, strategic asset
There’s a pattern that shows up consistently across enterprise AI deployments – a model performs well in the test environment and quietly falls apart in production.
The model is almost never the problem. The data is.
AI models are only as reliable as the inputs they receive. A credit scoring model trained on biased historical data will produce biased outputs – precisely and consistently. A medical diagnosis assistant fed stale clinical records will miss patterns that have already shifted in the real world. A fraud detection engine built on data from one regulatory environment will misfire in another.
Data governance is what prevents all of this. It covers three interconnected areas:
- Data quality – ensuring training and inference data is accurate, complete, and current
- Data lineage – tracking where every piece of data came from, how it was transformed, and which model versions it fed into
- Data governance frameworks – the policies, stewardship roles, and processes that enforce quality and lineage standards across the AI lifecycle
Through 2025, 85% of AI projects that failed did so not because of model performance, but because of data, process, and organizational issues. That number should be on every CTO’s dashboard.
Lineage specifically matters for more than just debugging. When a model produces an unexpected output – a loan rejection, a clinical flag, a risk alert – lineage is how you trace back through the decision chain. Which dataset? Which version? Which transformation? Without it, you cannot answer a regulator’s question, a client’s complaint, or your own post-mortem.
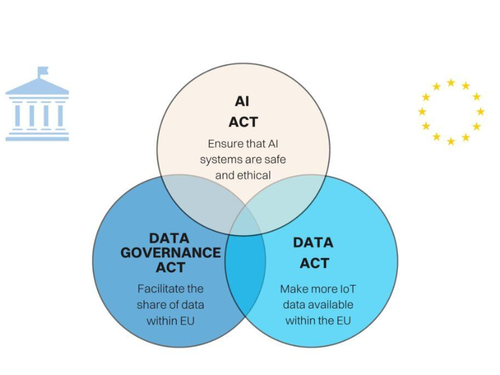
EU Compliance Requirements on Data Governance
The EU AI Act is not a vague principles document. It specifies, with legal precision, what data governance requirements apply to high-risk AI systems – and those requirements are already binding for systems currently in production.
For high-risk AI systems – which include credit scoring, hiring tools, medical device AI, and employee monitoring systems – the Act mandates the following data governance obligations:
- Training data must be representative, relevant, and free from known errors
The Act requires that training datasets cover the populations the system will affect. Statistical gaps, underrepresented groups, or historical bias in the data must be identified, documented, and addressed before deployment.
- Data governance documentation must be maintained and available for audit
Every high-risk system must have written documentation describing its training data: sources, collection methodology, preprocessing steps, and known limitations. This documentation must stay current – it is not a one-time exercise.
- Dataset versioning and model reproducibility are required
If a regulator asks you to reproduce the exact output your model produced on a given date, you must be able to do it. That requires versioned datasets tied to versioned models – a capability most organizations are not yet running.
- Logging of data inputs in production
The AI Act mandates automatic logging of all data inputs into high-risk AI systems. Every inference event – the data that went in, the output that came out, the timestamp – must be traceable. This is not just good practice: it is a legal record.
Switzerland and the EU AI Act:
Switzerland is not an EU member, but Swiss enterprises serving EU markets are effectively within scope for their EU-facing AI deployments. FINMA has begun requesting AI governance disclosures aligned with EU standards, and the Swiss Federal Council is developing national AI regulation closely mirroring the EU framework.
3. Strategies for Trustworthy Data
Bias mitigation starts before training, not after
Most bias mitigation conversations happen after a model is already performing badly. That is the wrong entry point. Bias is a data problem, and it needs to be addressed when data is collected, labeled, and preprocessed – not when a compliance team notices a pattern in model outputs.
Practically, this means auditing training datasets for statistical representation across all groups the model will affect. It means using stratified sampling when historical data underrepresents certain populations. And it means documenting the bias-testing methodology so that both internal reviewers and regulators can inspect it.
Automated Validation and Cleansing
Unvalidated inputs are a leading cause of production AI failures. Implement automated rules during data ingestion to ensure data adheres to standards. Use tools for data cleansing to correct errors, remove duplicates, and ensure consistency.
This is not a one-time fix. Production data changes. Schemas drift. APIs change their output formats. Validation logic needs to be maintained alongside the model itself.
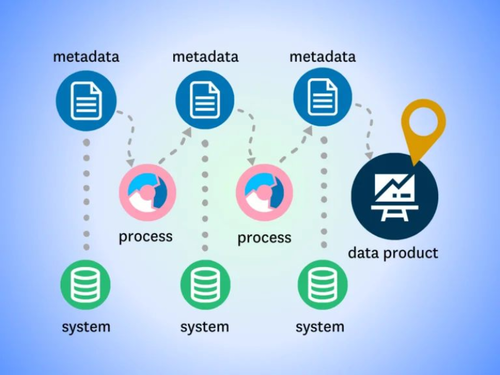
Metadata Management and Data Cataloging
Data lineage requires metadata – structured information about every dataset: where it came from, when it was last updated, what transformations were applied, and which model versions consumed it. Without a data catalog, lineage tracing is a manual exercise that will fail under audit pressure.
Modern data catalogs automate metadata capture and make lineage queries answerable in seconds. For organizations running multiple AI systems simultaneously – a common situation in financial services and healthcare – centralized metadata management is not optional: it is the only way to maintain cross-system coherence.
Secure Data Handling and Data Observability
Implement encryption and role-based access controls to maintain security, privacy, and regulatory compliance. Use AI-driven monitoring to proactively identify and rectify data quality issues in real-time before they impact business intelligence.
4. Choose Appropriate Data Lineage Tools & Technologies
No single lineage tool covers every technology perfectly. Below is a concise overview of the leading data lineage tools to consider
4 Best Commercial Data Lineage Tools to Consider
- Atlan: Active metadata and end-to-end lineage platform for the modern data & AI stack, with column-level tracing, impact analysis, and AI-ready governance.
- Alation Data Intelligence: A legacy enterprise catalog offering data discovery, glossary management, and metadata documentation with basic lineage capabilities.
- Collibra Data Intelligence Platform: Governance-heavy platform with stewardship workflows, compliance capabilities, and visual lineage for regulated enterprises.
- Informatica Intelligent Data Management Cloud (IDMC): A metadata and lineage solution embedded in the Informatica ecosystem, supporting large multi-cloud environments.
Top 3 Open-source Data Lineage Tools to Consider
- Apache Atlas: A governance and metadata framework commonly used in Hadoop and on-prem ecosystems; supports classification and lineage.
- OpenLineage + Marquez:
- OpenLineage: An open standard for lineage metadata collection across pipelines.
- Marquez: A metadata service and lineage backend for that helps visualize the metadata captured by OpenLineage.
- OpenMetadata: A unified open-source metadata repository offering cataloging, lineage, quality, and governance APIs.
The architecture decision that matters most is not which individual tool you choose – it is whether these tools are integrated into a single lineage graph rather than operating as isolated silos. Lineage that only covers part of the pipeline is not lineage: it is a map with missing terrain.
5. What Bad Data Governance Looks Like
Fintech: Citigroup Data Governance Failure
Citigroup’s massive regulatory fines expose the critical cost of poor data governance and broken data lineage. Without transparent, end-to-end lineage to trace data origins, Citi struggled with fragmented silos, inaccurate reporting, and severe compliance issues.
This opacity directly fueled flawed risk models and costly operational errors. For enterprises, the lesson is stark: robust governance isn’t just a regulatory checkbox; it is the foundation of reliable analytics.
Establishing clear data lineage guarantees data quality, prevents catastrophic model failures, and ensures compliance. Prioritize enterprise data governance to safeguard your models and maintain regulatory trust.
Healthcare: Healthcare Network Achieves Patient Safety Through Data Quality
The Problem
A major hospital network with multiple facilities discovered a critical problem: 12% duplicate patient records were causing wrong-patient alerts, delayed care, and potential safety issues. With no data governance program in place, they had 8 different definitions of “active patient” across departments, making coordination nearly impossible.
Our Solution
Implemented a master patient index (MPI) with sophisticated fuzzy matching algorithms that could identify duplicates even with variations in names, addresses, and birth dates.
Created data quality scorecards for each source system and established a data governance council with defined ownership for each data domain. Automated quality monitoring provided continuous visibility into data health.
6. Building Your Data Governance Roadmap
Governance roadmaps fail when they start with tooling. They succeed when they start with inventory.
- Step 1: Build a data inventory – List every dataset currently feeding your AI systems. Include source, owner, update frequency, and a preliminary assessment of whether it is representative of the population affected by the model. This inventory is the foundation everything else is built on.
- Step 2: Assign data stewardship roles – Every dataset needs an owner: a person accountable for its quality, documentation, and freshness. Without ownership, governance is a document that nobody maintains. In larger organizations, a Data Stewardship Committee with representation from IT, legal, and the business unit deploying the AI is the right model.
- Step 3: Implement pipeline-level validation – Add validation layers at every data ingestion point. Define what “acceptable data” looks like for each pipeline and automate the check. Tools like Great Expectations can codify these definitions and generate the documentation that compliance reviews will ask for.
- Step 4: Deploy a data catalog and start capturing metadata – Atlan, Databricks Unity Catalog, or an equivalent platform will centralize your metadata and begin building the lineage graph. Start with your highest-risk AI systems and expand from there.
- Step 5: Version your datasets and link them to model versions – Implement DVC or equivalent tooling. Ensure every model in production has a documented data provenance record: which dataset version, which preprocessing pipeline, which evaluation results. This is the artifact your auditors will ask for.
- Step 6: Set up continuous monitoring and drift detection – A model that is well-governed at launch will degrade as real-world data shifts away from its training distribution. Production monitoring for both data quality and model performance is the governance layer that makes the others meaningful over time.
Where to start if you are resource-constrained:
Prioritize governance for your highest-risk AI systems first – specifically any system making decisions about credit, employment, healthcare, or customer access. These are the systems the EU AI Act classifies as high-risk and where compliance obligations are most immediate. A focused governance framework on two or three systems, done well, is more defensible than a superficial policy covering everything.
Conclusion
AI data governance is not a compliance checkbox. It is the infrastructure that makes AI systems trustworthy, auditable, and improvable over time. The lineage record is also the debugging tool. The data stewardship role is also the person who keeps the model current as the world changes.
Getting it right requires a deliberate decision to build governance into AI architecture from the start. The roadmap is clear. The tooling exists. The regulatory clock is running.
IMT Solutions helps enterprises across Switzerland, the EU, and the US build AI pipelines with governance embedded at every layer – from data ingestion to model deployment and monitoring
Our teams work alongside yours to close the gaps. See our case studies or contact IMT Solutions to discuss your AI data governance roadmap.
Frequently Asked Questions About AI Data Governance
What is data governance?
Data governance is a set of processes, policies, and standards that ensure the effective management of data within an organization. It defines roles, responsibilities, and procedures to maintain data quality, security, privacy, and compliance.
What are the benefits of data governance?
Some of the benefits of data governance include data consistency, compliance with data regulations, increased transparency, enhanced data security, and better decision-making.
What is Data Lineage?
Data lineage shows the history of the data you’re looking at today, detailing where it originated and how it may have changed over time. It’s a reflection of the data life cycle, the source, what processes or systems may have altered it, and how it arrived at its current location and state.
How does data lineage improve data quality?
Data lineage allows teams to perform root-cause analysis by tracing data quality issues back to their source transformation. It prevents “context erosion” by showing exactly how a metric was calculated before reaching a dashboard.
What are the Top Data Lineage Tools?
Top data lineage tools for 2026 include enterprise-grade platforms like Collibra, Informatica, and Alation for comprehensive governance, alongside modern active metadata platforms such as Atlan and Manta for deep, automated technical lineage. Microsoft Purview is optimal for Azure environments, while OpenMetadata and Apache Atlas lead in open-source options
Does GDPR compliance cover the EU AI Act’s data governance requirements?
No. GDPR and the EU AI Act have overlapping scope but different obligations. GDPR governs how personal data is collected, stored, and processed. The EU AI Act governs how AI systems behave – their design, training data, human oversight mechanisms, and auditability. For high-risk AI that also processes personal data, both frameworks apply simultaneously, and compliance with one does not satisfy the other. Organizations running AI in financial services, healthcare, or HR across the EU need both compliance tracks.
How do data governance requirements differ for general-purpose AI (GPAI) models?
GPAI models have their own obligations under the EU AI Act, separate from the high-risk tier. These include training data transparency, copyright compliance documentation, and for the most powerful models, systemic risk assessments. Critically: when a GPAI model is integrated into a high-risk application (a credit decision workflow, a hiring tool), the integrating organization inherits the full high-risk classification, including all data governance requirements. Fine-tuning a public LLM on proprietary data may also reclassify the organization as an AI provider, with full provider obligations.







